Splitting a Document
Overview
A common cause for errors or degraded performance is when you try to apply a Schema to a document, where that document has many irrelevant or repeated parts. Examples:
Example Use Cases
- Your Schema expects to extract invoice details into a Standardization that has fields like invoice ID, total amount - but the PDF you're ingesting has multiple invoices stuck together into one big file, violating your assumption that there's just one invoice ID. You'd like to run on each invoice separately.
- Your Schema is built to normalize the contents of an operations manual, but it contains repetitions in English + many other languages, causing duplicate extractions or results being extracted in an inconsistent language. You want to only extract the sub-document which is in English, and discard the rest.
- You have many Class definitions, each with their own Schema that you want to run on them, but you ingest a single giant document. For example, maybe you're ingesting a patient referral, and it includes a large PDF that contains multiple lab reports, clinician notes, prescriptions, etc.
Scenario - Split a Long Rental Lease
Here's a Rental Lease that spans 51 pages.
First upload this document onto DocuPipe. Then head to the Documents Tab. Hover over the document you're interested in splitting, then hover over the "..."
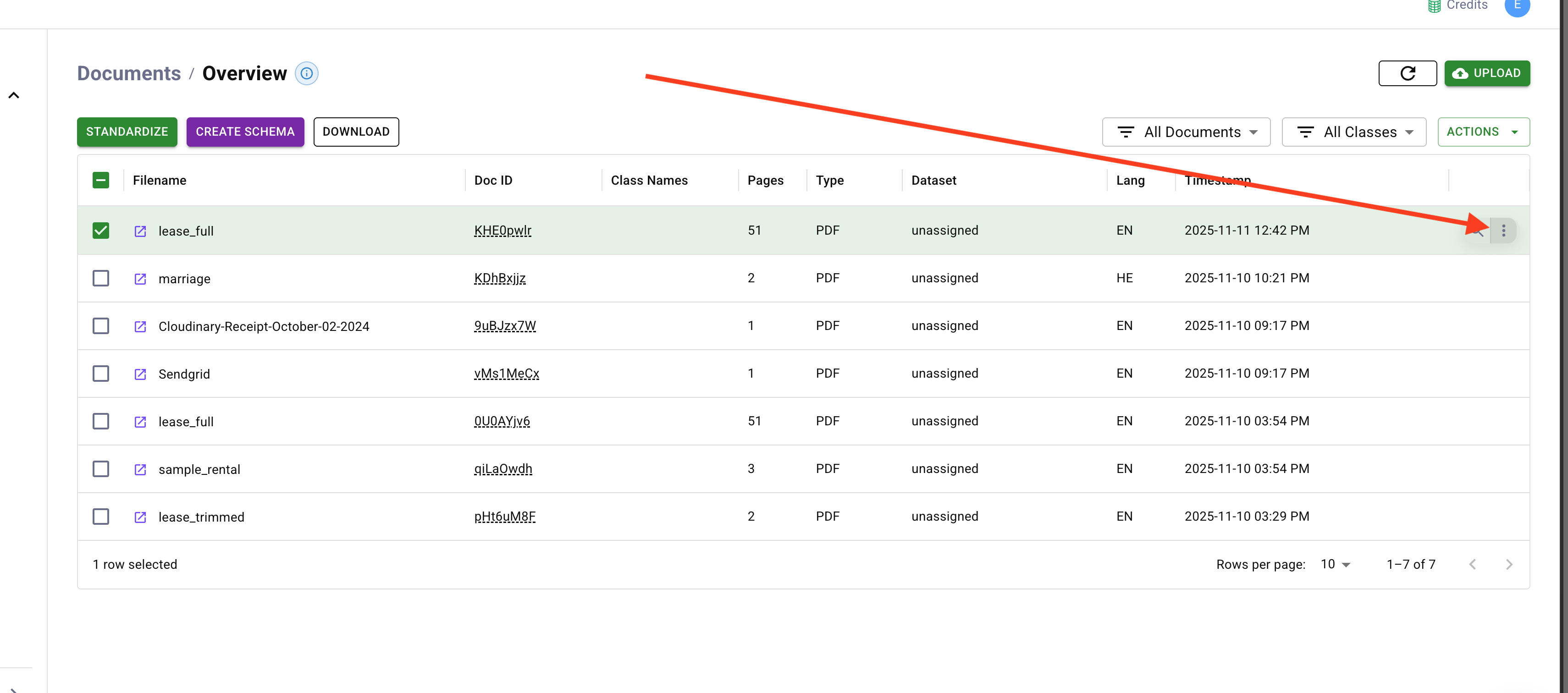
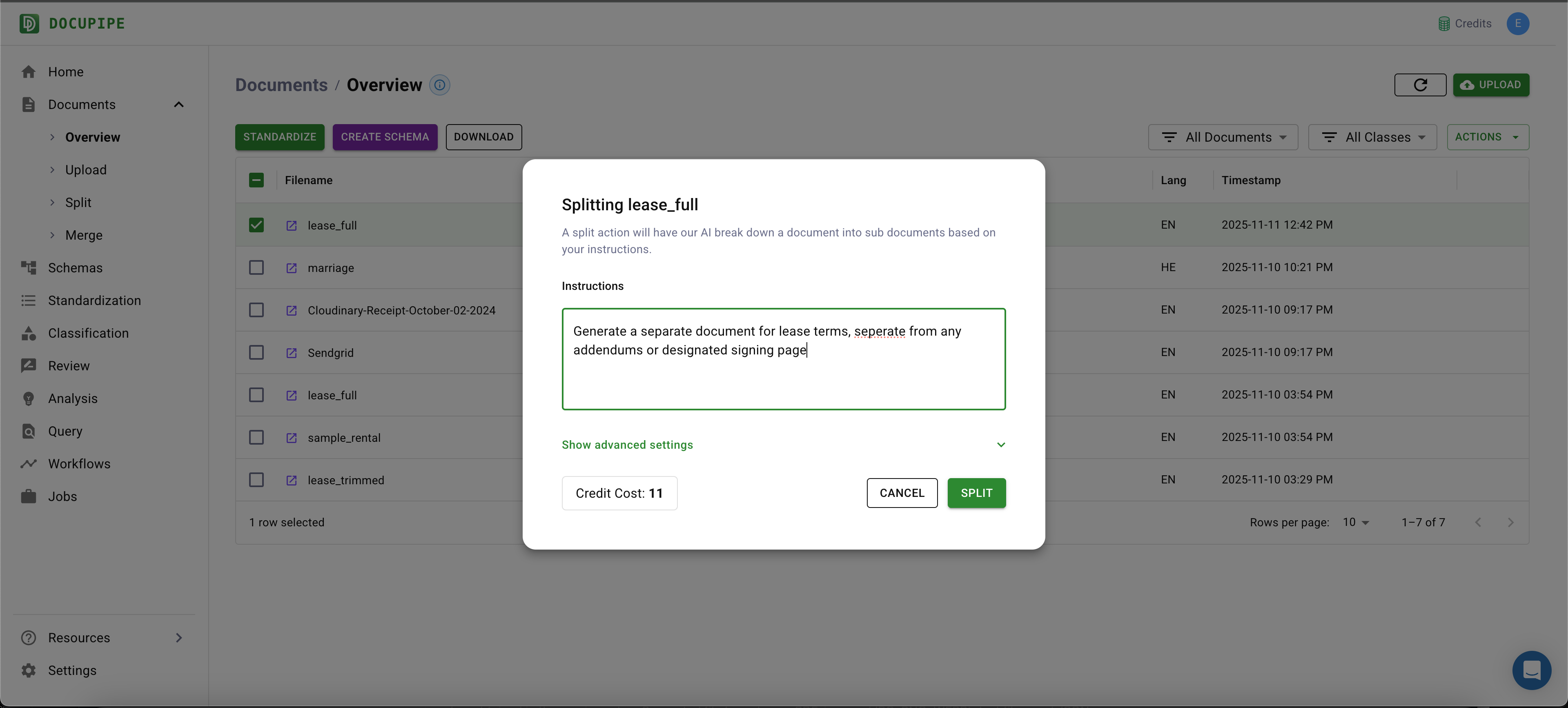
This will bring into view a popup. Let's give it a reasonable extraction prompt. For example, we can use this prompt:
You will then see a Job populate in the Jobs Tab, and once it's complete, if you go back to the Documents Tab you will see that you have many new sub-documents. By default the AI renames the documents to give you an idea of what sub-documents it has pulled up.
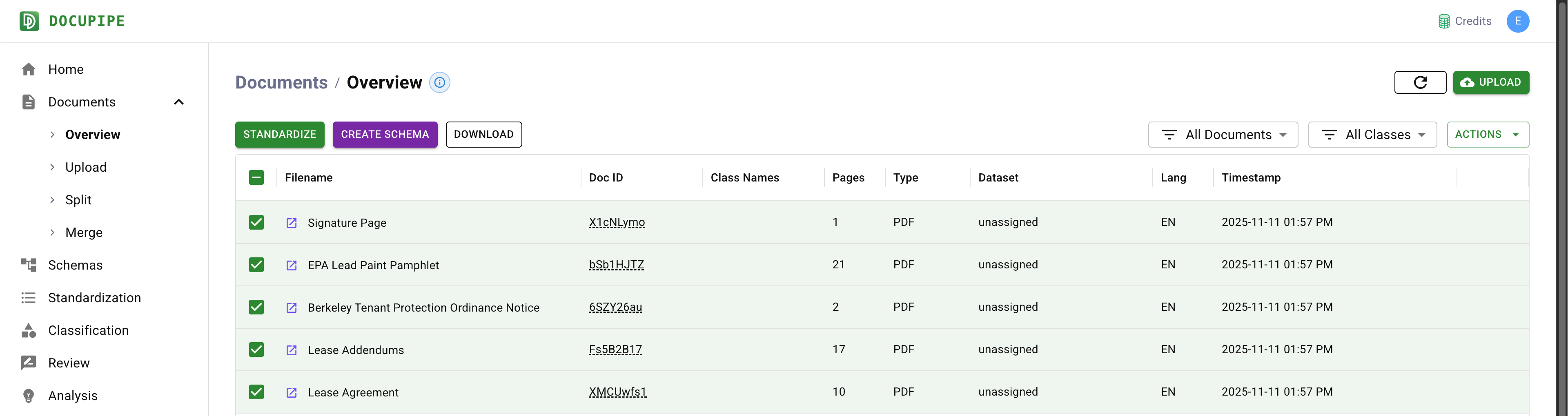
Let's click on the "Berkeley Tenant Protection Ordinance Notice" to see if the results are sane.
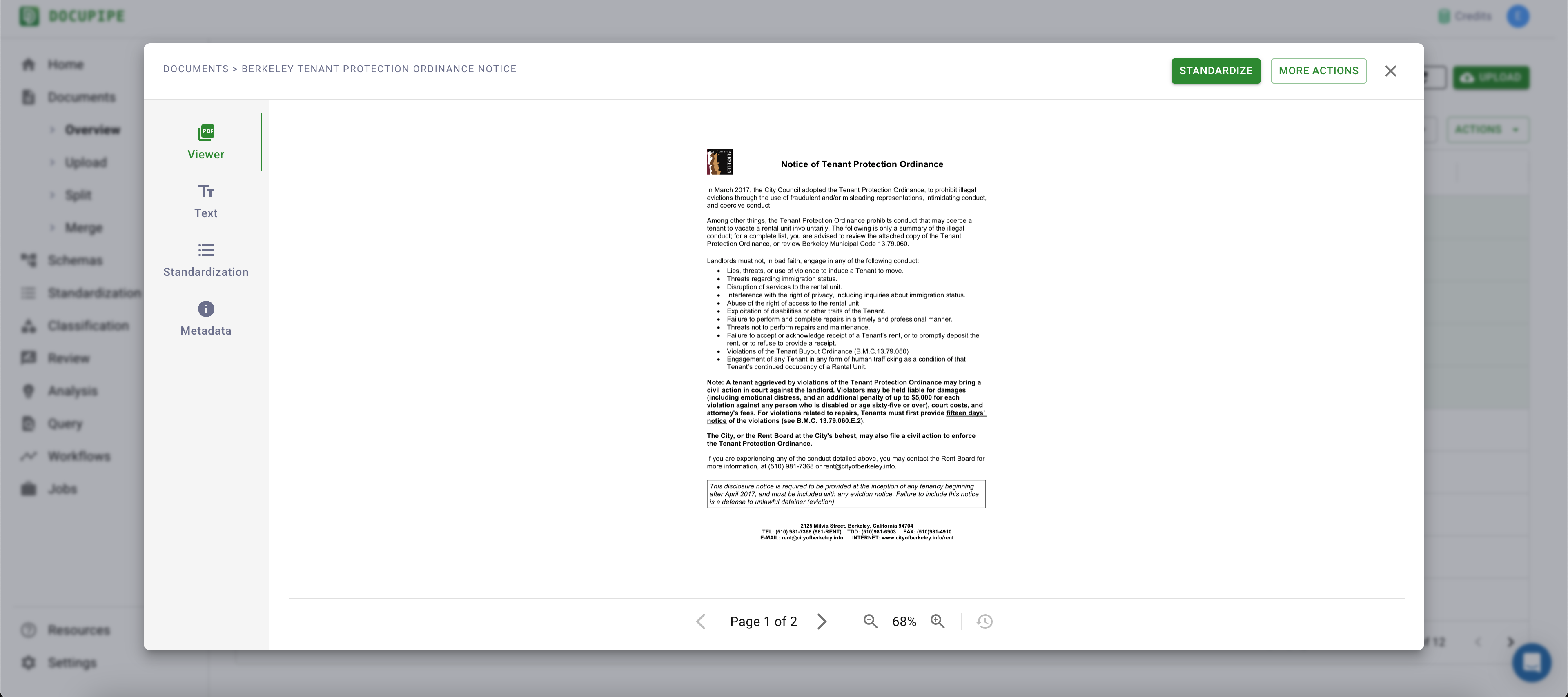
Nice, looks like it grabbed a well-defined sub-document here.
Let's say we want to normalize the signature page and the Lease agreement only. If we've already built a schema, we can run the appropriate schema on each sub-document, and standardize it.
Next Step
A typical process for splitting is that you want to split a document, classify every output sub-document, and standardize each sub-document with the right Schema. You can read about how to define a Class under Configuring Classes. Read on to the next guide to see how to tie together Split -> Classify -> Standardize with the appropriate schema for each class.