Troubleshooting Extractions
What to do when something is missed in a Standardization you've generated
Overview
Sometimes you're not happy with a Standardization you've extracted from a document. Usually, you're just a couple of configuration steps away from a reliable, consistent result. Below you will find the steps used to bring your extraction to high consistency and quality.
Short Version
- Select a standardization you're not happy with, and hit
Improve, this will let you talk to the AI and explain what is missed/wrong and improve results - Change the standardization parameter Effort Level from standard to high, if the document is particularly complex
Most Common Fix - Improve Your Schema
Example 1: Missing Information
Your schema includes field names and descriptions, as well as Guidelines. These have a large impact on how the AI understands its task and formats the results.
Here's an example: maybe your extracted Standardization looks like the screenshot below, and you don't like that the extracted amounts do not include a currency symbol.
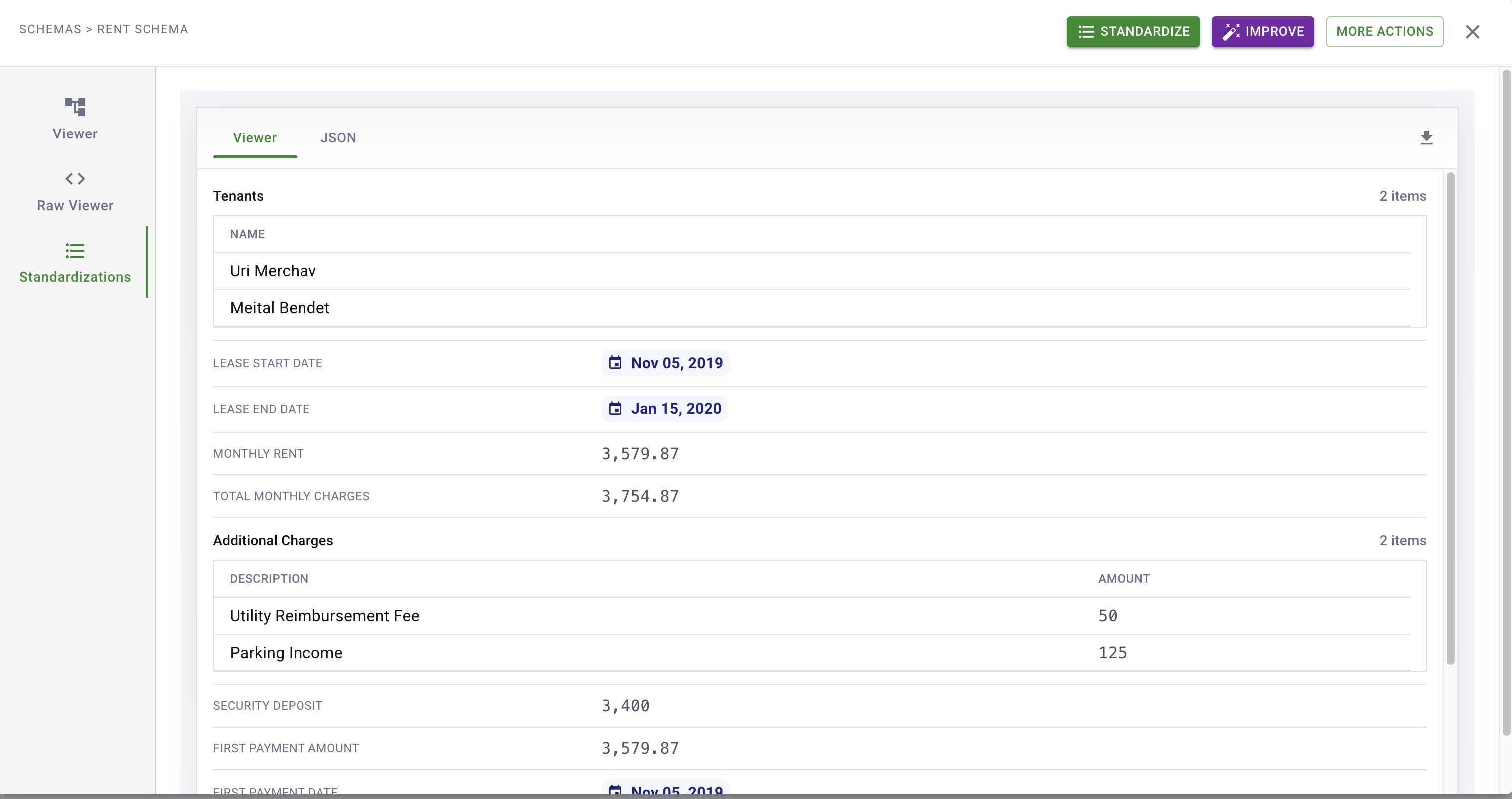
This example of a mistake is a straightforward schema definition issue. If we take a look at our schema, we can see it has no slot for currency symbols. We can fix this in one of two ways:
- Directly edit the schema by clicking on edit, and adding a field called currencySymbol
- Click on the purple "Improve" button and explain to our AI in interactive chat what got missed, letting it figure out a new schema.
In this guide, we'll choose the latter option. Clicking on "Improve", we get a chat window where we can go back and forth with the AI and explain the changes required. For example:
"We extracted amounts correctly, but we don't have their currency. Add a currency symbol as a separate field for every extracted value (like e.g. USD)."
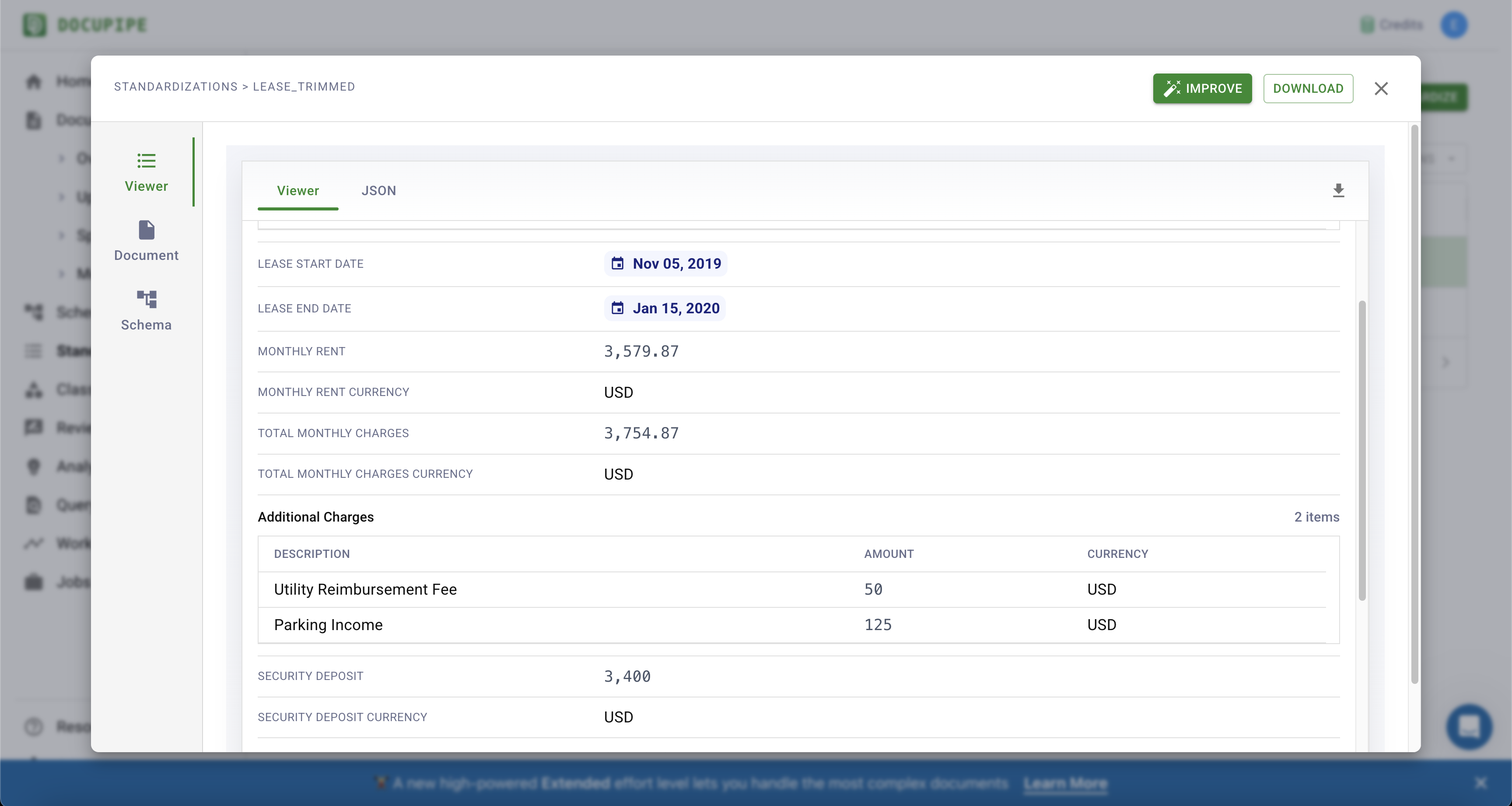
Click Generate Schema, and after a few minutes you'll receive an improved version. Manually run the new schema on a few documents to make sure the results look good: select the schema, click Standardize, and examine the outcome. Here it is, now with USD.
Example 2: Misunderstanding
Often the reason something is mis-extracted is that the schema is too vague. For example, maybe your schema has a field called VatId, and you're normalizing an invoice that says "company number: 12345." You know that "company number" is a VAT ID for your business, but the AI does not.
There are two ways to fix this:
- Again as before, you can select the incorrect standardization, hit
Improve, and carefully explain to the AI its mistake, and it will propose its own edits to the schema to clarify the nuance for itself. - You can directly update the Guidelines attached to the schema. They can contain any free text that disambiguates the extraction job. Example Guidelines:
- "The
VatIdfield is sometimes shown as "company number". Map any company number toVatId." - "In purchase orders, never extract the name
ACME INC.. that's our own company. Only extract information relating to the vendor, which will be a company other thanACME INC."
- "The
Here's where you edit the Guidelines:
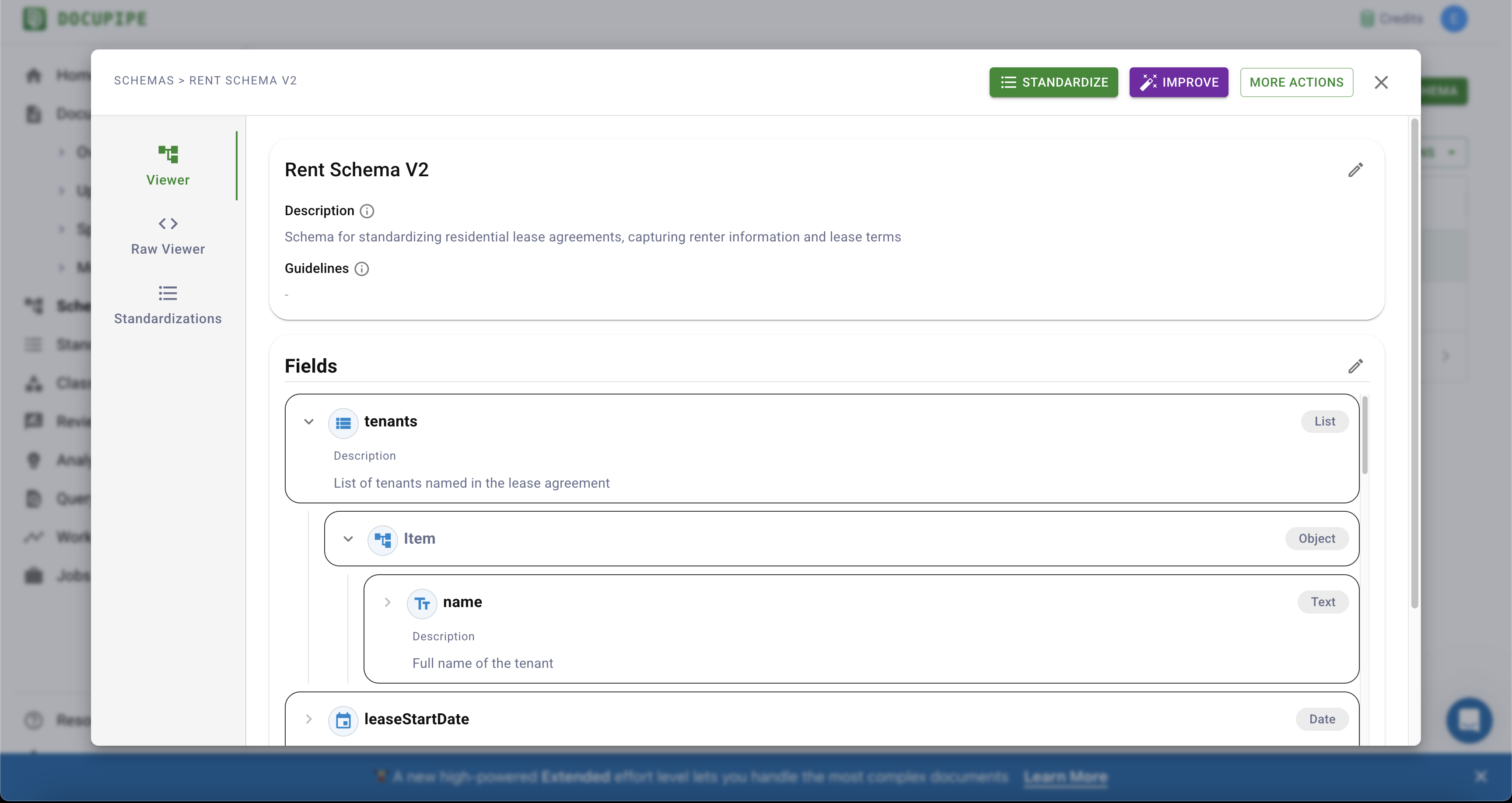
Click on the little edit pencil, edit the Guidelines, and type in any disambiguation.
Changes to your Guidelines edit the existing schema in place, so rerun standardize with the updated schema after saving.
Split Your Document
Sometimes you create a schema with the intention to run on one input, and then end up accidentally putting in a document that has multiple inputs. Example: you expect a utility bill to have 1 account number, usage period, and total amount - and then your system ingests a PDF that contains many different accounts and periods all in one document.
The fix here is to use DocuPipe's Split operation. You can read more about it Here. Split takes in a document plus instructions and breaks a long file into sub-documents. On the Documents tab in your dashboard, click Split.
Select the document you want to split and describe, in plain language, how the pages should be grouped.
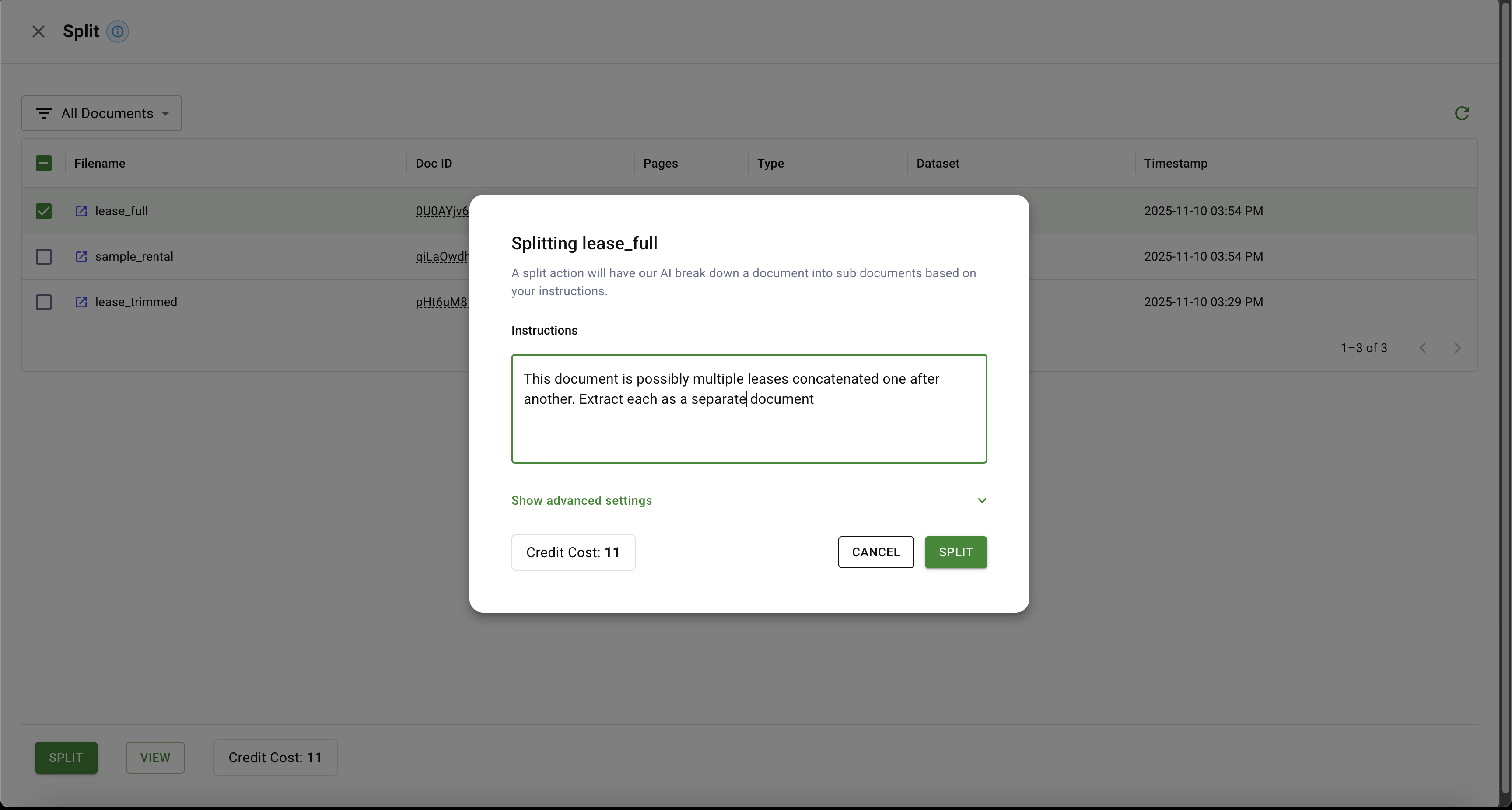
Our AI is smart enough not to split if it detects only a single underlying document. Split is also handy when you want to focus on a narrow page span inside a long PDF or disentangle many concatenated documents intelligently.
Many DocuPipe users end up building a flow that runs Split the same way every time. You can define a workflow that first splits a document and then runs Classification to determine which schema should process each subdocument.
Change Standardization Configuration
When you run standardization, either through our UI or manually, you can set the Effort Level. 90% of the time the default is good enough, but sometimes you need to tweak it.
Effort Level
This is the most powerful lever you can pull to improve results. Set Effort Level to High. High effort uses more capable models, so it consumes 4 credits per page instead of 2 in standard mode. Reach for it on long, dense, or complex documents where standard misses fields.
There's no display mode or split mode to configure. Our extraction engine reads each page, handles layout, and splits long documents automatically - effort level is the only knob you set.